Proč 90% AI projektů selhává? Kompletní průvodce přípravou dat pro AI

Úvod: Skrytá pravda o AI projektech
Koupili jste si drahý AI nástroj. Nasadili ho. A teď? Halucinuje. Odpovídá nesmysly. Vrací zastaralé informace.
Proč? Protože jste přeskočili ten nejdůležitější krok – přípravu dat.
Podle zprávy Data Trust Report 2025 až 41% organizací přiznává problémy s udržením konzistentní kvality dat, což negativně ovlivňuje implementaci AI řešení. A to je jen špička ledovce.
„Špatná data = špatná AI. Tak jednoduché to je.”
V tomto článku vám ukážeme:
- Proč je kvalita dat kritická pro úspěch AI
- 4 hlavní problémy RAG projektů (95% selhává v produkci)
- Jak správně připravit data pro RAG systémy
- 5 chunking strategií s konkrétními příklady
- Co je RAGus.ai a jak řeší problém halucinací
Hlavní problémy RAG & Gen AI projektů
95% RAG projektů selhává v produkci. Proč? Identifikovali jsme 4 hlavní příčiny:

Problém #1: Struktura dat
Jak nahrát firemní data (desítky tisíc nestrukturovaných URL a dokumentů) do znalostní báze ve strukturovaném formátu?
- A: Data jsou nahraná do KB bez preprocessingu a struktury
- B: KB nedokáže vrátit validní informace pro přesnou odpověď bez halucinací
- C: Data musí být kvalitní a unikátní (odstranění zbytečného boilerplate)
Problém #2: Chunking
V ideálním světě by každý dokument nebo URL seděl ve vlastním chunk s vyčištěnými informacemi.
Realita:
- Vektorové databáze mají limity: 500–4096 tokenů na chunk
- Většina platforem používá naivní strategie:
- Dělení obsahu po pevném počtu tokenů
- Povoleno 800-1500 tokenů na chunk
- Text useknut uprostřed věty
- Kontext ztracen = vyhledávání selhává
- Fixní překryv tokenů
Problém #3: Metadata
Každý chunk potřebuje bohatá a detailní metadata:
- Původ (název souboru, číslo stránky, URL odkaz)
- Pole pro filtraci
- Shrnutí aktuálního chunku
- Shrnutí překryvu s předchozím chunkem
- Shrnutí zdrojové stránky
Problém #4: Automatické aktualizace
- KB postavena jednou, nikdy neaktualizována
- AI vrací zastaralé informace
- Nebo rovnou halucinuje
💡 Nechcete to řešit sami? Jako AI společnost s více než 30 úspěšně dokončenými projekty nabízíme přípravu dat na klíč. Od auditu po finální integraci — my se postaráme o vše.
Co je RAG a proč je klíčem k přesné AI
Retrieval-Augmented Generation (RAG)
RAG je technologie, která kombinuje vyhledávání relevantních informací s generativními schopnostmi AI modelů.

Místo toho, aby AI odpovídala pouze ze svých trénovaných znalostí (které mohou být zastaralé), RAG:
- Retrieval (Vyhledávání): Najde relevantní dokumenty ve znalostní bázi
- Augmentation (Obohacení): Přidá nalezené informace do kontextu
- Generation (Generování): AI vygeneruje odpověď na základě aktuálních dat
Proč RAG funguje lépe než klasické LLM
| Aspekt | Klasické LLM | RAG |
|---|---|---|
| Aktuálnost dat | ❌ Zastaralé (trénink) | ✅ Aktuální (živá data) |
| Citace zdrojů | ❌ Nelze ověřit | ✅ Odkaz na zdroj |
| Halucinace | ❌ Časté | ✅ Minimální |
| Přesnost | ~70-80% | 90-99% |
Jak správně připravit data pro AI
4-krokový proces přípravy dat

Krok 1: Zmapování zdrojů
Projdeme všechno – web, dokumenty, databáze, e-maily, interní systémy. Zjistíme, co máte a v jakém stavu.Krok 2: Čištění a sjednocení
Pryč s duplicitami. Pryč s nekonzistencemi. Jeden zdroj pravdy. Jedna struktura.Krok 3: Obohacení a rozdělení
Přidáme metadata, shrnutí, souvislosti. Rozdělíme optimální strategií. AI pak ví, kde hledat.Krok 4: Vytvoření "druhého mozku"
Vše nahrajeme do jedné znalostní báze – vašeho centrálního zdroje pravdy.💡 Nechcete to řešit sami? Nabízíme profesionální přípravu dat na klíč. Zkušenosti z 30+ projektů.
Chunking strategie: Kompletní průvodce s příklady
AI nečte celé dokumenty. Pracuje s "chunky" – kousky textu. Jak je rozdělíte, tak vám bude odpovídat.
Špatné dělení = špatné výsledky.
Příklad textu pro všechny strategie
Pro srovnání použijeme stejný text o vesmírném teleskopu Kepler:
# The Kepler Space Telescope
The Kepler space telescope was a space observatory launched by NASA to discover Earth-size planets orbiting other stars. It was named after astronomer Johannes Kepler.
## Mission Overview
Kepler's sole instrument was a photometer that continually monitored the brightness of approximately 150,000 main sequence stars in a fixed field of view. It looked for periodic dimming, known as transits, caused by planets crossing in front of their host star.
## Major Discoveries
During its nine-year mission, Kepler observed 530,506 stars and confirmed 2,662 planets. A key finding was that 20-50% of stars visible to the naked eye likely have small, rocky planets similar in size to Earth.
## End of Operations
The mission ended in 2018 when the spacecraft ran out of fuel. The telescope was deactivated, but its data continues to yield new discoveries.Strategie 1: Dělení podle pevné velikosti (Fixed Size)
Technický název: Recursive Character Splitter / Fixed Token Count
Jak funguje: Rozdělí text každých N tokenů, bez ohledu na obsah.
Příklad výstupu:
| Chunk | Obsah | Problém |
|---|---|---|
| 1 | "The Kepler space telescope was a space observatory... ## Mission Overview Kepler's sole instrument was a" | ❌ Useknutí uprostřed věty |
| 2 | "photometer that continually monitored the brightness... caused by planets crossing in" | ❌ Začíná i končí uprostřed věty |
| 3 | "front of their host star. ## Major Discoveries During its nine-year mission..." | ❌ Míchá nesouvisející sekce |
✅ Vhodné pro: Když je rychlost důležitější než kvalita, nebo máte omezený rozpočet.
❌ Nevýhody: Často usekne myšlenky, ztrácí kontext.
💰 Náklady: Nízké | 📈 Kvalita: ⭐ Nízká
Strategie 2: Dělení podle nadpisů (Header-Based)
Technický název: Markdown Header Chunking
Jak funguje: Hledá nadpisy (#, ##) a drží vše pod každým nadpisem pohromadě.
Příklad výstupu:
| Chunk | Obsah |
|---|---|
| 1 | # The Kepler Space Telescope — "The Kepler space telescope was a space observatory... named after Johannes Kepler." |
| 2 | ## Mission Overview — "Kepler's sole instrument was a photometer... planets crossing in front of their host star." |
| 3 | ## Major Discoveries — "During its nine-year mission, Kepler observed 530,506 stars..." |
| 4 | ## End of Operations — "The mission ended in 2018 when the spacecraft ran out of fuel..." |
✅ Perfektní! Každá sekce zůstává kompletní.
❌ Omezení: Nefunguje, pokud dokument nemá nadpisy (chat, e-maily, transkripty).
💰 Náklady: Nízké | 📈 Kvalita: ⭐⭐ Střední
Strategie 3: Dělení podle významu (Semantic Chunking)
Technický název: Semantic Chunking
Jak funguje: AI měří, jak "podobná" je každá věta té následující. Když se téma výrazně změní, vytvoří nový chunk.
Příklad výstupu:
| Chunk | Proč seskupeno |
|---|---|
| "The Kepler space telescope was a space observatory... It looked for periodic dimming, known as transits." | AI vidí "telescope," "instrument," "monitor" jako související koncepty |
| "During its nine-year mission, Kepler observed 530,506 stars and confirmed 2,662 planets..." | Čísla a objevy = nové téma |
| "The mission ended in 2018 when the spacecraft ran out of fuel..." | "End," "deactivated" = téma ukončení |
✅ Výhoda: Seskupuje myšlenky i bez nadpisů v dokumentu.
❌ Nevýhoda: Pomalejší, vyžaduje ladění.
💰 Náklady: Střední | 📈 Kvalita: ⭐⭐⭐ Vysoká
Strategie 4: AI-rozhodnuté dělení (Agentic/LLM-Based) ⭐
Technický název: LLM-Based Chunking / Agentic Chunking
Jak funguje: AI přečte celý text a sama rozhodne o nejlepších místech pro rozdělení na základě logiky a toku.
⚠️ Důležité: Proč NEPOSÍLAT AI celý text k označení
- 💰 Drahé (duplikuje všechny vstupní tokeny jako výstup)
- 🐢 Pomalé (masivní generování výstupu)
- ❌ Riziko halucinací (AI může změnit originální text)
- 📏 Omezení výstupního okna
Správný 3-fázový proces:
FÁZE 1: Pre-split s indexovými tagy (bez AI)
Text se rozdělí na malé kousky (~50 tokenů) s číselnými tagy:
<chunk_0>The Kepler space telescope was a space observatory launched by NASA to discover Earth-size planets orbiting other stars.</chunk_0>
<chunk_1>It was named after astronomer Johannes Kepler. Kepler's sole instrument was a photometer that</chunk_1>
<chunk_2>continually monitored the brightness of approximately 150,000 main sequence stars in a fixed field of view.</chunk_2>
<chunk_3>It looked for periodic dimming, known as transits, caused by planets crossing in front of their host star.</chunk_3>
<chunk_4>During its nine-year mission, Kepler observed 530,506 stars and confirmed 2,662 planets.</chunk_4>
<chunk_5>A key finding was that 20-50% of stars visible to the naked eye likely have small, rocky planets similar in size to Earth.</chunk_5>
<chunk_6>The mission ended in 2018 when the spacecraft ran out of fuel.</chunk_6>
<chunk_7>The telescope was deactivated, but its data continues to yield new discoveries.</chunk_7>FÁZE 2: AI rozhodnutí (minimální výstup – jen čísla!)
AI dostane prompt: "Vrať POUZE indexy chunků, kde mají vzniknout sémantické zlomy."
AI Response: split_after: 0, 3, 5, 7✅ AI vypíše pouze ~10 tokenů, ne celý dokument!
FÁZE 3: Programové spojení (bez AI)
Na základě split_after: 0, 3, 5, 7 se chunky spojí:
| Finální Chunk | Zdroj | Obsah |
|---|---|---|
| 1 | chunk_0 | "The Kepler space telescope was a space observatory launched by NASA..." |
| 2 | chunks 1-3 | "It was named after astronomer Johannes Kepler. Kepler's sole instrument was a photometer..." |
| 3 | chunks 4-5 | "During its nine-year mission, Kepler observed 530,506 stars and confirmed 2,662 planets..." |
| 4 | chunks 6-7 | "The mission ended in 2018 when the spacecraft ran out of fuel. The telescope was deactivated..." |
✅ Výsledek: AI rozhodla o sémanticky optimálních bodech, originální text zachován přesně, nízké náklady na tokeny.
💰 Náklady: Střední | 📈 Kvalita: ⭐⭐⭐⭐ Velmi vysoká
Strategie 5: Sumarizace / Q&A Formát
Technický název: Structured Output / Q&A Format / Propositional Indexing
Jak funguje: Místo zachování originálního textu extrahuje čistá fakta jako páry otázka-odpověď nebo strukturovaný JSON.
Příklad výstupu:
| Otázka | Odpověď |
|---|---|
| Co byl Kepler Space Telescope? | Observatoř NASA pro objevování planet velikosti Země. |
| Jaký nástroj Kepler používal? | Fotometr monitorující jas hvězd. |
| Kolik planet Kepler potvrdil? | 2 662 planet. |
| Kolik hvězd Kepler pozoroval? | 530 506 hvězd. |
| Proč mise skončila? | Vesmírná loď vyčerpala palivo v roce 2018. |
✅ Vhodné pro: FAQ systémy, databáze, když uživatelé kladou konkrétní dotazy.
❌ Nevýhoda: Ztrácí příběh a kontext mezi fakty. Může halucinovat.
💰 Náklady: Vysoké | 📈 Kvalita: ⭐⭐⭐⭐ Velmi vysoká
📊 Srovnávací tabulka chunking strategií
| # | Strategie | Technický název | Co dělá | ✅ Výhody | ❌ Nevýhody | 💰 Náklady | 📈 Kvalita |
|---|---|---|---|---|---|---|---|
| 1 | Fixed Size | Recursive Character Splitter | Řeže po N tokenech | Rychlé, jednoduché | Usekne věty, ztrácí kontext | 💲 Nízké | ⭐ |
| 2 | By Headers | Markdown Header Chunking | Dělí podle nadpisů #, ## | Drží sekce pohromadě | Vyžaduje strukturu | 💲 Nízké | ⭐⭐ |
| 3 | By Meaning | Semantic Chunking | AI detekuje změnu tématu | Chytrá seskupení | Pomalejší, vyžaduje ladění | 💲💲 Střední | ⭐⭐⭐ |
| 4 | AI-Decided ⭐ | LLM-Based / Agentic | AI čte a rozhoduje o zlomem | Zvládá chaotický text | Vyžaduje AI zpracování | 💲💲 Střední | ⭐⭐⭐⭐ |
| 5 | Summarization | Structured Output / Q&A | Převádí na otázka-odpověď | Perfektní pro FAQ | Ztrácí narativ | 💲💲💲 Vysoké | ⭐⭐⭐⭐ |
💡 Pro Tip: Pokud AI-Decided chunking vytvoří chunk, který přesahuje limit vaší vektorové databáze (např. 8000 tokenů), kombinujte s Summarizací. AI rozhodne o hranicích → následně se příliš velké chunky kondenzují.
Jak zvýšit kvalitu vyhledávání (Enhancement strategie)
Samotný chunking je jen základ. Špičkové RAG systémy používají vylepšovací techniky, které každému kousku textu dodají "supervlastnosti":
Přidání kontextu dokumentu (Document Summary)
Ke každému chunku přidáme globální kontext – název dokumentu, hlavní téma.
Bez kontextu (problém):
"The mission ended in 2018 when the spacecraft ran out of fuel."❌ AI neví, která mise!
S Document Summary:
[Zdroj: NASA Kepler Space Telescope mission (2009-2018), exoplanet detection]
"The mission ended in 2018 when the spacecraft ran out of fuel."✅ Teď vyhledávání "fuel" nebo "Kepler" vrátí chunk, který dává smysl sám o sobě.
Vyhledávací klíčová slova (Search Keywords)
Před samotný text vložíme pravděpodobné otázky a klíčová slova:
kepler fuel end mission 2018 shutdown why did kepler stop | The mission ended in 2018...Srovnání Enhancement strategií
| Vylepšení | Co dělá | 💰 Náklady | 📈 Kvalita |
|---|---|---|---|
| Document Summary | Přidá kontext ke každému chunku | 💲💲 Střední | ⭐⭐⭐ |
| Search Keywords | Přidá vyhledávací dotazy | 💲💲💲 Vysoké | ⭐⭐⭐⭐ |
| Kombinace obou | Maximální přesnost | 💲💲💲 Vysoké | ⭐⭐⭐⭐⭐ Elitní |
Co dělá data "AI-ready"?
7 klíčových vlastností kvalitních dat

- Celé myšlenky, ne útržky – Text není useklý v půlce věty. AI dostane kompletní informaci.
- Jasná hierarchie – AI přesně ví, kde hledat odpovědi a kde jsou pomocná data.
- Předpřipravené otázky – Ke každému bloku jsou přiřazené otázky, na které odpovídá.
- Shrnutí u každého bloku – AI okamžitě chápe kontext, nemusí číst celý dokument.
- Propojení mezi částmi – Každý blok ví, co bylo před ním. AI chápe souvislosti.
- Metadata pro filtraci – Datum, kategorie, zdroj. AI může hledat přesně tam, kde má.
- Původ každé informace – AI může citovat zdroj a vy víte, že to není vymyšlené.
Příklad: Špatná vs. dobrá data
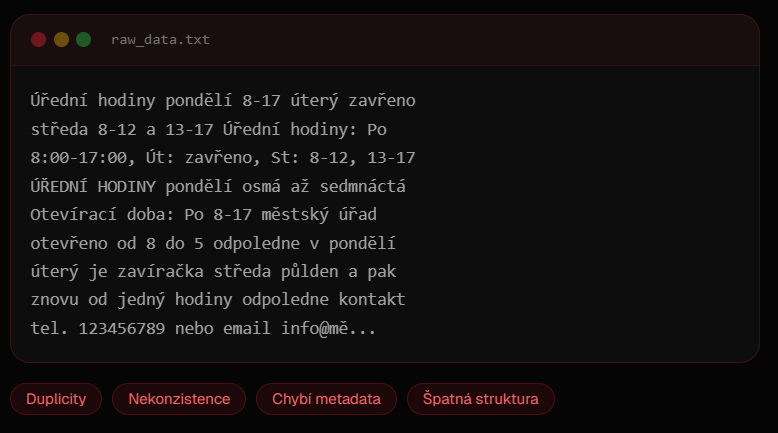
❌ Typická realita (raw_data.txt):
Chaos. Duplicity. Chybějící kontext. AI hádá.
Úřední hodiny pondělí 8-17 úterý zavřeno
středa 8-12 a 13-17 Úřední hodiny: Po
8:00-17:00, Út: zavřeno, St: 8-12, 13-17
ÚŘEDNÍ HODINY pondělí osmá až sedmnáctá
Otevírací doba: Po 8-17 městský úřad
otevřeno od 8 do 5 odpoledne v pondělí
úterý je zavíračka středa půlden a pak
znovu od jedný hodiny odpoledne kontakt
tel. 123456789 nebo email info@mě...🏷️ Problémy: Duplicity | Nekonzistence | Chybí metadata | Špatná struktura
✅ Po naší přípravě (chunk_001.json):
Čistá struktura. Metadata. Kontext. AI ví.
{
// Vektorově vyhledatelná pole
"searchableFields": {
"rag_question": "Jaké jsou úřední hodiny městského úřadu?",
"content": "Úřední hodiny: Po 8-17, Út zavřeno, St 8-12 a 13-17",
"source_page_summary": "Kontaktní stránka MÚ",
"current_chunk_summary": "Otevírací doba úřadu",
"overlap_summary": "...kontaktní údaje a adresa"
},
// Filtrovatelná metadata
"metadataFields": {
"source_url": "mestsky-urad.cz/kontakt",
"category": "úřední hodiny",
"date_int": 20250115,
"language": "cs",
"chunk_index": 3
}
}🏷️ Výhody: Optimalizováno pro RAG | Plná metadata | Bez duplicit | Jasná hierarchie
RAGus.ai: Naše řešení problému
Co je RAGus.ai?
RAGus.ai je naše specializovaná RAG-as-a-Service platforma určená:
- AI agenturám
- Enterprise AI týmům
- RAG vývojářům
- No-code builderům (Voiceflow, Botpress)
Klíčové funkce
| Funkce | Popis |
|---|---|
| Centralizovaný dashboard | Správa všech AI produktů na jednom místě |
| Pokročilá analytika | Statistiky konverzací, detailní reporting |
| Integrovaný helpdesk | Efektivní řešení dotazů a eskalací |
| Přímé napojení | OpenAI, Voiceflow, Pinecone, Qdrant |
| 5 chunking strategií | Včetně agentního (LLM) chunkingu |
| Rychlé vyhledávání | Odpovědi v milisekundách |
| Enterprise bezpečnost | SOC 2, bankovní šifrování |
Jak RAGus.ai řeší halucinace
- Čistá a strukturovaná data – Automatické čištění a deduplikace
- Automatická synchronizace – Znalostní báze je vždy aktuální
- Monitoring odpovědí – Kontinuální vylepšování
- Zpětná vazba – Palec nahoru/dolů pro trénování
Výsledek: 90%+ přesnost ihned, až 99% do 3 měsíců.
Čistá a strukturovaná data — základ úspěšné AI
Kvalitní AI asistent je jen tak dobrý, jak dobrá jsou data, která mu dáte. RAGus.ai je náš vlastní administrační panel, který slouží jako centrální mozek pro všechny vaše AI produkty. Stará se o to, aby vaše znalostní báze byla vždy aktuální, přehledná a bez chyb.
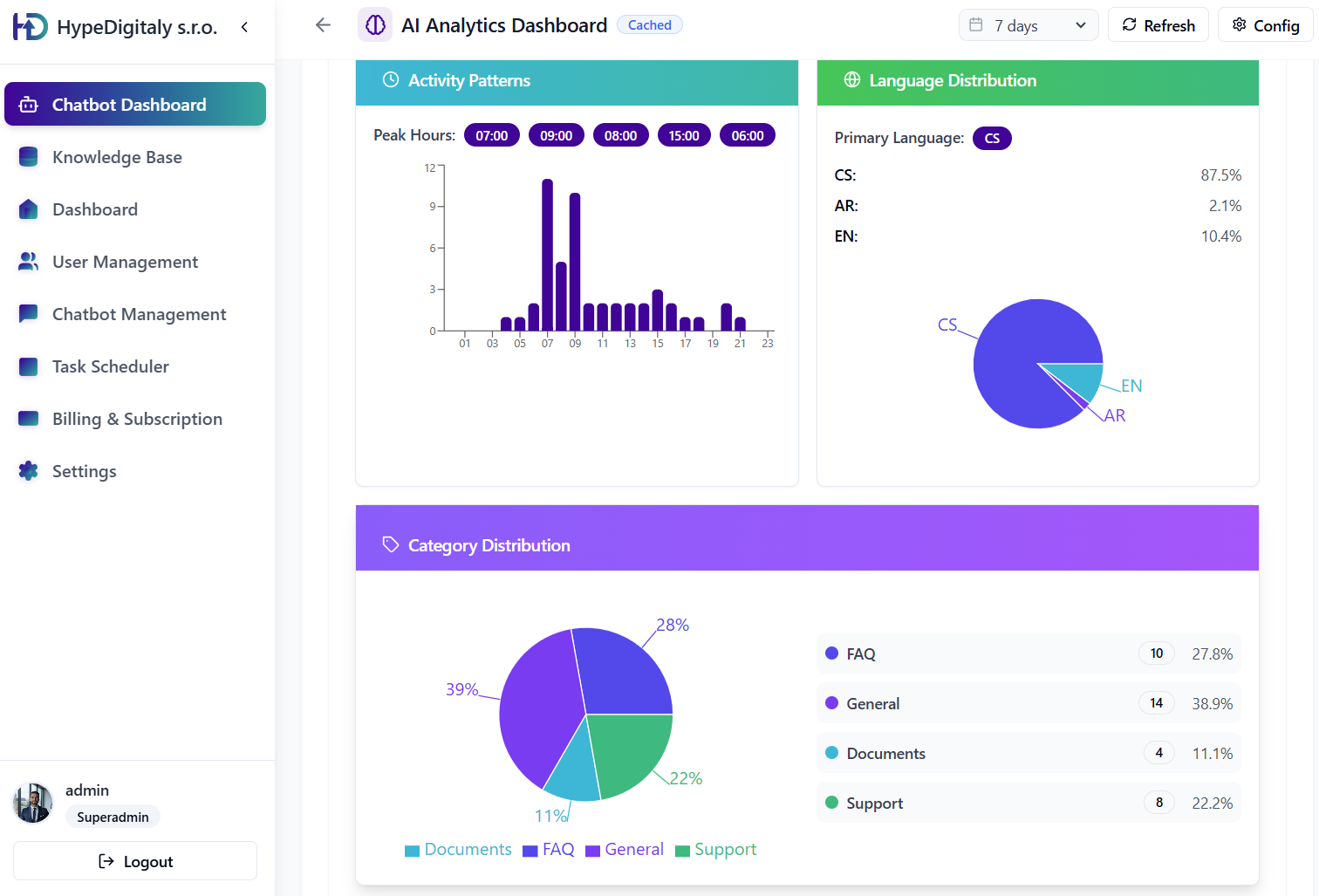




Samostatná úprava znalostí
Klient si může chatbota vylepšovat a opravovat sám přes admin panel bez nutnosti programování.
Transkripce a hodnocení
Možnost procházet historii konverzací a označovat úspěšné či neúspěšné interakce pro další učení.
Analýza sentimentu a trendů
Kategorizace nejčastějších dotazů a sledování spokojenosti uživatelů v reálném čase.
Dvě cesty: Služba vs. Self-service
Profesionální služba (doporučeno)
Pro koho:
- Nemáte kapacitu řešit přípravu dat
- Chcete garantovaný výsledek bez starostí
- Oceníte expertní vedení a podporu
Cena: od 2 500 Kč/hod nebo od 15 000 Kč za datový zdroj
👉 Objednat přípravu dat na klíč
RAGus.ai Self-service
Pro koho:
- Máte technický tým a chcete kontrolu
- Potřebujete automatizaci a škálování
- Stavíte vlastní AI produkty
Cena: od $49.99/měsíc
Závěr a další kroky
Klíčové poznatky
- 95% RAG projektů selhává kvůli špatné struktuře dat
- 4 hlavní problémy: Struktura, Chunking, Metadata, Aktualizace
- 5 chunking strategií – od jednoduché po AI-řízenou
- Enhancement techniky dramaticky zvyšují přesnost
- RAGus.ai nabízí kompletní řešení od přípravy po monitoring
Vytvořte si svůj "druhý mozek" pro AI
Nezáleží, kde máte data ani v jakém formátu. Vše propojíme do jednoho uceleného místa – znalostní báze, ze které AI čerpá.
Žádné hledání. Žádné hádání. Žádné halucinace.
*Máte zájem o bezplatnou konzultaci? Kontaktujte nás a ukážeme vám, jak z rozházených dat vytvořit jeden ucelený zdroj pravdy.*
Chcete dosáhnout podobných výsledků?
Domluvte si bezplatnou konzultaci a zjistěte, jak může AI transformovat vaši organizaci.
Bezplatná konzultace